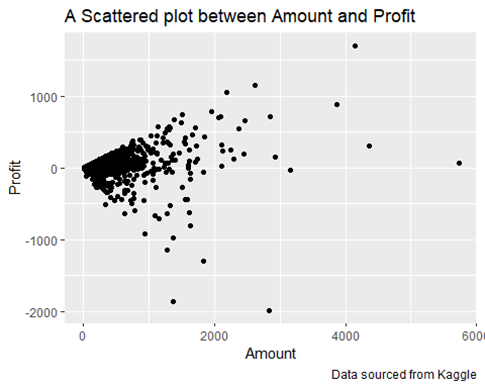
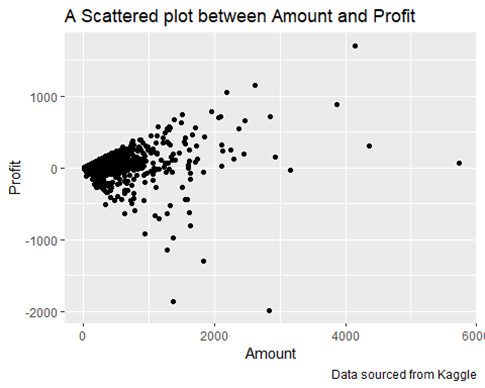
- Examining the output and plot, it’s clear that there is a very low correlation between Quantity and Profit. This indicates that profit does not rely on the quantity sold. In other words, selling more items does not necessarily lead to higher profits. This suggests that other factors, such as pricing, cost of goods, or operational efficiency, might be influencing profitability more than the sheer volume of sales.
- What is the percentage achievement of sales targets for each category?
In resolving the above business question, i started by joining both Sales_Table and Sales_Target tables using the Full Join function and housed it in a new variable
Target_Table<- full_join(Sales_Table, Sales_Target)
## Joining with `by = join_by(Category)`
## Warning in full_join(Sales_Table, Sales_Target): Detected an unexpected many-to-many relationship between `x` and `y`.
##  Row 1 of `x` matches multiple rows in `y`.
Row 1 of `x` matches multiple rows in `y`.
## Row 13 of `y` matches multiple rows in `x`.
## If a many-to-many relationship is expected, set `relationship =
## “many-to-many”` to silence this warning.
I went ahead to calculate the percentage achieved for each category
Target_Achieved<-Target_Table %>%
select(Category, Sales, Target) %>%
group_by(Category) %>%
summarise(Total_Sales = sum(Sales),
Total_Sales_Target = sum(Target),
Percentage_Achieved = (Total_Sales/Total_Sales_Target)*100)
print(Target_Achieved)
## # A tibble: 3 × 4
## Category Total_Sales Total_Sales_Target Percentage_Achieved
## <chr> <int> <int> <dbl>
## 1 Clothing 7974264 165126000 4.82920
## 2 Electronics 9798996 39732000 24.66273
## 3 Furniture 7989180 32294700 24.73836
Finally, i rounded off the output and Concatenated the “%” symbol
Target_Achieved$Percentage_Achieved<-round(Target_Achieved$Percentage_Achieved, 2)
Target_Achieved$Percentage_Achieved <- paste0(Target_Achieved$Percentage_Achieved,”%”)
print(Target_Achieved)
## # A tibble: 3 × 4
## Category Total_Sales Total_Sales_Target Percentage_Achieved
## <chr> <int> <int> <chr>
## 1 Clothing 7974264 165126000 4.83%
## 2 Electronics 9798996 39732000 24.66%
## 3 Furniture 7989180 32294700 24.74%
- Based on the analysis, Furniture led in target achievement with a 24.74% rate, closely matching the performance of Electronics. Despite running at a loss, the data indicates demand, and with adjustments, profitability could be achieved. Electronics ranked second with a 24.66% achievement rate, outperforming Clothing but still showing room for improvement. This relatively higher achievement suggests stronger performance or more effective sales strategies for this category. Clothing achieved only 4.83% of its sales target, indicating a significant shortfall. This suggests potential issues in sales strategies or market conditions affecting clothing sales. However, it is important to note that higher targets were often allocated to clothing, possibly due to its higher profitability compared to other categories.
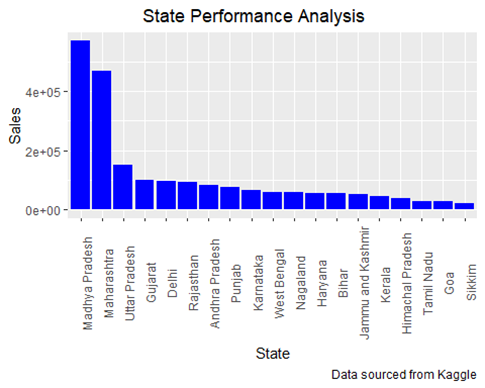
- How does the sales performance vary across different states?
State_Sales<- Sales_Table %>%
select(State, Sales) %>%
group_by(State) %>%
summarise(Tol_Sales = sum(Sales)) %>%
arrange(desc (Tol_Sales))
print(State_Sales)
## # A tibble: 19 × 2
## State Tol_Sales
## <chr> <int>
## 1 “Madhya Pradesh” 569685
## 2 “Maharashtra” 467660
## 3 “Uttar Pradesh” 150032
## 4 “Gujarat” 100292
## 5 “Delhi” 97071
## 6 “Rajasthan” 94050
## 7 “Andhra Pradesh” 82897
## 8 “Punjab” 77591
## 9 “Karnataka” 66231
## 10 “West Bengal” 58035
## 11 “Nagaland” 57985
## 12 “Haryana” 54891
## 13 “Bihar” 54082
## 14 “Jammu and Kashmir” 53201
## 15 “Kerala ” 46158
## 16 “Himachal Pradesh” 39850
## 17 “Tamil Nadu” 29195
## 18 “Goa” 27919
## 19 “Sikkim” 20045
Visualizing the above
State_Sales$State<- factor(State_Sales$State, levels = State_Sales$State[order(-State_Sales$Tol_Sales)])
ggplot(State_Sales, aes(x = State, y = Tol_Sales)) +
geom_bar(stat = “identity”, fill = “blue”) +
labs(title = “State Performance Analysis”, X = “State”, y = “Sales”, caption = “Data sourced from Kaggle”)+
theme(axis.text.x = element_text(angle = 90)) + theme(plot.title = element_text(hjust = 0.4))